
Last year I successfully passed 70-762. This post will is my raw notes I used to study and pass the test. I used a variety of sources to study, including Pluralsight, the official practice test, and reading the documentation at docs.microsoft.com. Unfortunately, this and many other exams are being retired on January 31, 2021, so if you’re studying, hurry!
Studying to-do:
- elastc scale shards – elastic database client library
- sql server resource governor
- lock types – intent/shared/exclusive
- partitions
- join types
- nested loop benefits from having an index to support seek operations against the inner table.
- nested loop is used with a large table and a small table.
- merge join
- requires that inputs are sorted in the order of their join columns
- Can use an index, since an index is in the order of their key columns.
- hash joins
- used for massive tables
- do not benefit from indexes
- nested loop benefits from having an index to support seek operations against the inner table.
- index include columns
- additional data at the leaf level of the index
- They’re not part of the key
- They can’t be used to seek.
- They’re used to avoid key lookups.
- additional data at the leaf level of the index
- data warehouses
- cardinality estimator
- https://docs.microsoft.com/en-us/sql/relational-databases/performance/cardinality-estimation-sql-server?view=sql-server-ver15
- Query Optimizer is a cost-based query optimizer.
- Cost is based on
- Total number of rows processed at each level of a query plan.
- Referred to as the cardinality of the plan.
- Cost model of the algorithm dictated by the operators used in the query.
- Total number of rows is an input param to this factor.
- Total number of rows processed at each level of a query plan.
- Cardinality estimation is primarily derived from histograms that are created when indexes or stats are created.
- Constraint information and logical rewrites sometimes determine cardinality.
- Sometimes cardinalities cannot be accurately calculated.
- Queries with predicates that use comparison operators between different columns of the same table.
- Queries with predicates that use operators and any of the following:
- No stats on the columns involved on either side of the operators.
- Distribution of values in the stats is not uniform, but the query seeks a highly selective value set.
- Especially true if the operator is anything other than equals.
- Predicate uses the not-equal comparison operator or the not logical operator.
- Queries that use any of the built-in functions or scalar-valued, user-defined function whose argument is not a constant.
- Queries vinolving joining columns through arithmetic or string concatenation operators.
- Queries that compare variables who values are not known when the query is compiled and optimized.
- Views
- Updatable views
- Requirements
- Any modifications (update/insert/delete) must reference columns from only one base table.
- Columns modified in the view must directly reference underlying table data.
- Cannot be derrved.
- No aggregates. e.g. avg, count, sum, min, max…
- No computation. e.g. computed from expression that uses other columns. Columns formed using set operators: union, union all, crossjoin, etc
- Cannot be derrved.
- Not affected by GROUP BY, HAVING, or DISTINCT
- TOP not used anywhere in select statement, together with WITH CHECK OPTION clause.
- Above restrictions apply to subqueries in FROM clause of view, just as they apply to view itself.
- Generally, database engine must be able to unambigiously trace modifications from view definition to one table.
- If requirements are an issue, consider:
- INSTEAD OF triggers
- INSTEAD OF trigger is executed instead of the data modification statement on which trigger is defined. This lets the user specify the set of actions that must happen to process the data modification statement.
- Therefor, if INSTEAD OF trigger exists on a view on a specific data modification statement (insert/update/delete), the corresponding view is updatable through that statement.
- Partitioned Views
- Partitioned views are updatable, subject to certain restrictions.
- The database engine distinguishes local partitioned views as the views in which all participating tables and the view are on the same instance of sql server, and distributed partitioned views as the views in which at least one of the tables in the view resides on a different/remote server.
- INSTEAD OF triggers
- Requirements
- Partitioned views
- A view defined by a UNION ALL of member tables structured in the same way, but stored separately as multiple tables in either the same instance of SQL SERVER, or in a group of autonomous instances of SQL Server servers, called federated database servers.
- The preferred method for partitioning data local to one server is through partitioned tables.
- When designing the scheme, it must be clear what data belongs to each partition.
- e.g.: –Partitioned view as defined on Server1 CREATE VIEW Customers AS –Select from local member table. SELECT * FROM CompanyData.dbo.Customers_33 UNION ALL –Select from member table on Server2. SELECT * FROM Server2.CompanyData.dbo.Customers_66 UNION ALL –Select from member table on Server3. SELECT * FROM Server3.CompanyData.dbo.Customers_99;
- Conditions for creating partitioned views
- In the column list of the view definition, select all columns in the member tables.
- Ensure columns in the same ordinal position of each select list are of the same type, including collations.
- Not sufficient for columns to be implicitly convertible types, as is generally the case for UNION.
- At least one column must appear in all the select lists in the same ordinal position.
- Constraints must be in such a way that any specified value of <col> can satisfy, at most one of the constraints so that the constraints form a set of disjointed or nonoverlaping intervals.
- Same column cannot be used multiple times in the select list.
- Partitioning column
- Partitioning column is part of the PRIMARY KEY of the table
- Cannot be computed, identity ,default, or timestamp.
- If more than one constraint on the same column i a member table, database engine ignores all the constraints and does not consider them when determining whether the view is a partitioned view. To meet the conditions of the partitioned view, ensure that there is only one partitioning constraint on the partitioning column.
- There are no restrictions on the updatability of the partitioning column.
- Indexed views
- First index created on a view must be a unique clustered index.
- After the first, you can create more nonclustered indexes.
- Improves query performance because the view is stored in the database the same way a table with a clustered index is stored.
- Query optimizer may use indexed views to speed up query execution. The view does not have to be referenced in the query.
- Must create the view with WITH SCHEMABINDING option.
- Indexed views require fixed values for several SET options.
- Otherwise some SET options can yield different results, such as if CONCAT_NULL_YIELDS_NULL is on, ‘abc’ + NULL returns NULL, but OFF returns ‘abc’.
- The following SET options must be set to the values shown whenever the following occurs:
- Indexes on the view are created.
- Base tables referenced in the view at the time the table is created.
- What?
- Any insert, update, or delete operation performend on any table that participates in the indexed view. Includes bulk copy, replication, and distributed queries.
- The indexed view is used by the query optimized to produce the query plan
- (So, always?)
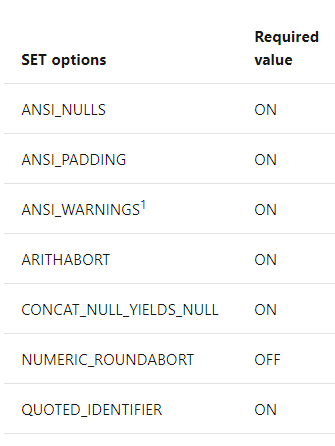
- Indexed views must be deterministic.
- All expressions in the select, where, and group by must be deterministic.
- Deterministic expressions always return the same result when they are evaluated with a given input.
- Only deterministic functions can participate in deterministic expressions.
- DATEADD works.
- GETDATE does not.
- You can use the IsDeterministic property of the COLUMNPROPERTY function to determine if a column is deterministic.
- Additional requirements
- User executing CREATE INDEX must be the owner of the view.
- IGNORE_DUP_KEY option must be set to OFF (the default) when creating an index.
- Tables must be referenced by two-part names, i.e. schema.tablename.
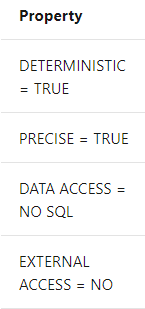
- Use-defined functions referenced in the view must be created using the WITH SCHEMABINDING option and be referenced by two-part names. i.e. schema.function.
- The data access property of a user-defined function must be NO SQL. External access property must be NO.
- CLR functions can appear in the select list of the view, but cannot be part of the clustered index key.
- CLR functions cannot appear in the WHERE clause or the ON clause of a JOIN.
- CLR functions and methods of CLR user-defined types used must have these properties set:
- The view cannot reference other views.
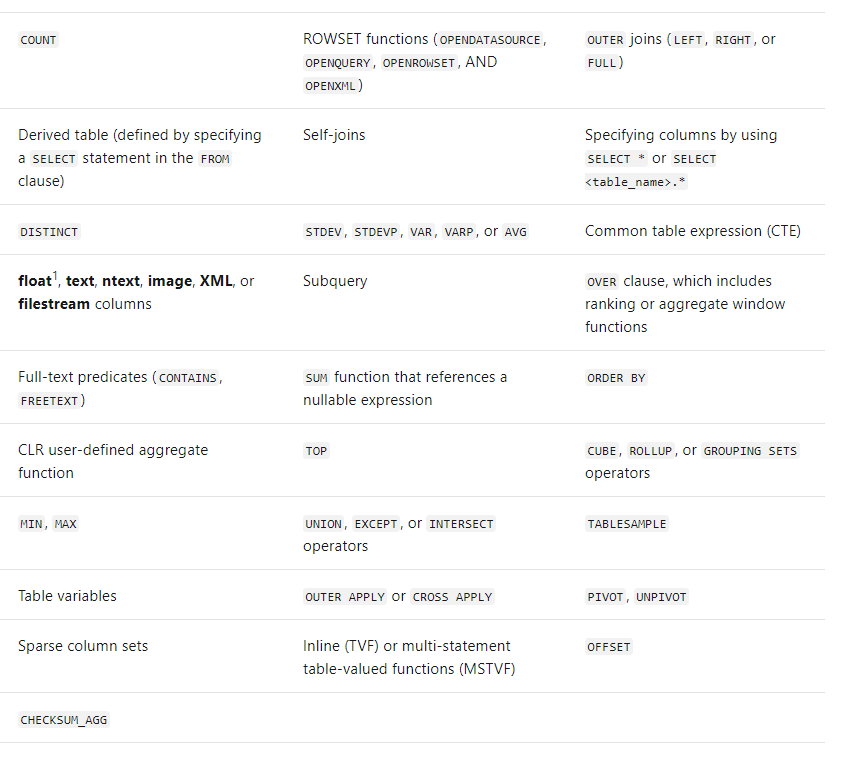
- SELECT cannot contain:
- If GROUP BY is present, view must contain COUNT_BIG and must not contain HAVING.
- And the key of the unique clustered index can only reference columns specified in the GROUP BY.
- Updatable views
Notes
- Memory optimized tables
- Optimizing performance of transaction process, data ingestion, data load, and transient data scenarios.
- Memory optimized tables are fully durable by default. Like disk-based tables, are fully atomic, consistent, isolated, and durable.
- Memory optimized tables and natively compiled stored procedures support only a subset of TSQL features.
- Primary storage is main memory. Rows are read/written to memory. A second copy is maintained on disk, only for durability purposes.
- Data is only read from disk during database recovery.
- Mark table as memory-optimized w/ Memory_Optimized=ON”
- DMV collects stats on query executions
- sys.dm_exec_query_stats
- DMV enables stats collection at query level
- sys.sp_xtp_control_query_exec_stats
- Natively compiled stored procedures do not support DISTINCT
- For greater perf gains, in-memory OLTP supports durable tables w/ transaction durability delayed.
- Delayed durable transactions are saved to disk soon after the transaction has committed and control was returned to client.
- In exchange for for increased perf, committed transactions that have not saved to disk are lost in a sever crash or failover.
- Also supports non-durable memory-optimized tables
- Not logged and data is not persisted to disk.
- Transactions on these tables do not require any disk IO, but data will not be recovered if there is a server crash or failover.
- Rows in memory are versioned.
- Each row in the table potentially has multiple versions.
- All row versions are maintained in the same table data structure.
- Row versioning is used to allow concurrent reads/writes on the same row.
- The memory-optimized data structure can be seen as a collection of row versions.
- Rows in disk-based tables are organized in pages and extents, and individual rows addressed using page number and page offset.
- Row versions in memory-optimized tables are addressed using 8-byte pointers.
- Each row in the table potentially has multiple versions.
- Data in memory-optimized tables is accessed in two ways:
- Through natively-compiled stored procedures.
- Through TSQL, outside of natively-compiled stored procedure. TSQL statements may be either inside interpreted stored procedures or may be ad-hoc TSQL statements.
- Accessed most efficiently from natively compiled stored procedures.
- But can still be accessed from traditional TSQL.
- Index operations are not logged, and only exist in memory.
- WITH DELAYED_DURABILITY = ON
- Writes to the memory-optimized table will use delayed writes to the transaction log
- DELAYED_DURABILITY ALLOWED
- Allows delaying the writes to transaction log by writing to the log asynchronously as a batch.
- Not supported
- After a memory-optimized table is created in a database, you can no-longer take a SNAPSHOT of the database.
- Cross-database transactions are not supported.
- READPAST table hint
- No column can be tagged for RowVersion.
- A SEQUENCE cannot be used with a constraint in a memory-optimized table.
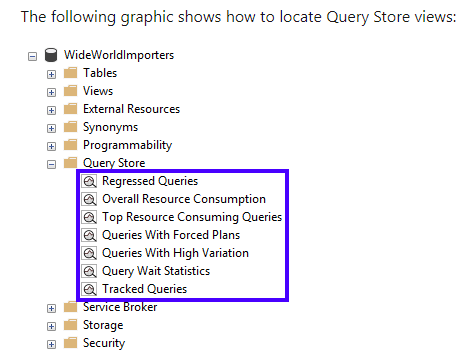
- SQL Query Store
- Provides insight on query plan choice and performance
- Captures history of queries, plans, runtime statistics.
- ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE);
- Cannot be enabled on master or tempdb
- Best Practices
- Max size MB
- When this limit is reached, query store changes to read-only and stops collecting new data, making your performance analysis no-longer accurate.
- 2016/2017 default value is 100MB. In 2019, default is 1GB.
- Value isn’t strictly enforced. Transitions when the value is checked, whenever it writes to disk.
- Keep track to prevent from transitioning to read-only mode.
- Data flush interval (minutes)
- Frequency to persist collected runtime stats to disk.
- Default 15 min.
- Choose higher if your workload doesn’t generate a large number of different queries and plans, or want to withstand a longer time to persist data before shutdown.
- trace flag 7745 prevents query store data being written to disk in case of failover or shutdown.
- Statistics collection interval
- Defines level of granularity for collected runtime statistic.
- Default 60 minute.
- Consider using lower value if you require finer granularity or less time to detect issues.
- Directly affects size of Query Store data.
- Stale Query Threshold (days)
- Time-based cleanup policy that controls retention period of persisted runtime stats and inactive queries.
- Default is 30 days.
- Avoid keeping historical data you don’t plan to use.
- Size-based cleanup mode.
- Specifies if data cleanup takes place when data size limit is reached.
- Specify Auto to make sure Query Store always runs in read-write mode.
- Max size MB
- Trace flag 7752
- Enables async load of Query Store.
- Allows database to become online before Query Store has fully recovered. Default behavior is do a sync load of Query Store.
- Starting in 2019, this trace flag has no effect.
- Includes plans for DML such as SELECT< INSERT,UPDATE,DELETE,MERGE and BULK INSERT.
- Does not collect data for natively compiled stored procedures by default.
- Starting with SQL Server 2017 (14.x) and Azure SQL Database, Query Store includes a dimension that tracks wait stats. The following example enables the Query Store to collect wait stats.
- ALTER DATABASE AdventureWorks2012
- SET QUERY_STORE = ON ( WAIT_STATS_CAPTURE_MODE = ON );
- Common scenarios for using the Query Store feature are:
- Quickly find and fix a plan performance regression by forcing the previous query plan. Fix queries that have recently regressed in performance due to execution plan changes.
- Determine the number of times a query was executed in a given time window, assisting a DBA in troubleshooting performance resource problems.
- Identify top n queries (by execution time, memory consumption, etc.) in the past x hours.
- Audit the history of query plans for a given query.
- Analyze the resource (CPU, I/O, and Memory) usage patterns for a particular database.
- Identify top n queries that are waiting on resources.
- Understand wait nature for a particular query or plan.
- The Query Store contains three stores:
- a plan store for persisting the execution plan information.
- a runtime stats store for persisting the execution statistics information.
- a wait stats store for persisting wait statistics information.
- Information is written to stores asynchronously.
- Number of unique plans that can be stored for a query is limited by max_plans_per_query configuration.
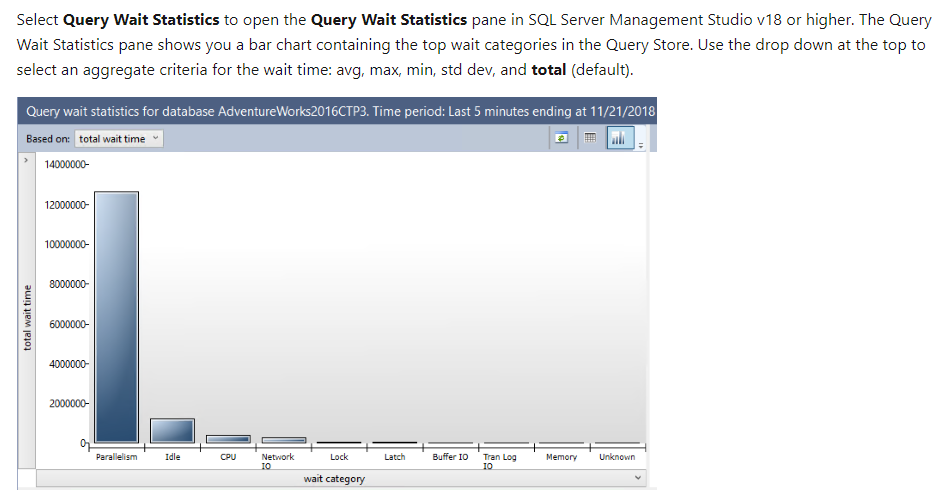
- Works with In-Memory OLTP
- Extended Events
- Enabled users to collect as much or little data as neccesary to troubleshoot problem.
- Scales very well. It’s basically ETW for SQL Server
- In SSMS, go to Management > Extended Events > New Session to create a new session.
- Creating an extended event session allows you to tell the system which occurrences you are interested in and how you want the system to report the data to you.
- CREATE EVENT SESSION [session name] ON SERVER ADD EVENT [sqlserver].[error_reported];
- You must have a minimum of 1 event.
- But nothing stops you from dropping it after it’s created.
- Predicates define logical rules for which an event can fire in a session.
- Defined in two ways:
- Basic operators
- textual comparators.
- Predicate limits to 3,000 characters.
- Predicates are evaluated in the logical order written
- Allows you to short-circuit
- Prefer event column over global data
- Actions execute sync on the firing thread
- You have to explicitly start sessions after creating them.
- You don’t have to stop in order to drop.
- DMVs
- sys.dm_xe_sessions
- Contains the event session name, memory buffer config, event loss info, date/time the event session started for each active event session on the sql server instance.
- sys.dm_exe_session_events
- Contains information about each of the events and the event predicates for the events defined in an active event session.
- sys.dm_xe_session_event_actions
- Contains one row for each action that is defined on an event in an active event session.
- sys.dm_xe_session_targets
- Contains the name, target type, execution stats, and XML column for each target that exists for an active event session.
- Data for memory-resident targets is in the XML column, and for persisted targets contains execution statistics.
- sys.dm_xe_session_object_columns
- Contains information about the conf options of each target, information about customizable columns for events in event session.
- sys.dm_xe_sessions
- Targets are data consumers.
- ring_buffer
- in-memory storage
- FIFO
- options
- max_memory
- max memory in KB to beused before older events are dropped
- binary, not the size of XML serialized by sys.dm_xe_session_targets
- occurrence
- preferred number of events to keep
- default is 0 – strict FIFO
- option can be affected by size of events that are being generated- may result in unexpected behavior under some workloads.
- max_event_limit
- max number of events kept in the target
- default is 1000
- available in sql server 2012+
- max_memory
- XML output
- is not schema bound by follows somewhat predictable output
- Single parent <RingBufferTarget>, contains attributes about target operation since starting
- eventsPerSec – num events processed /second
- processingTime – amount of time spent processing memory buffers
- totalEventsProcessed – total events processed
- eventCount – total events in ring_buffer
- droppedCount – total memory buffers dropped
- memoryUsed – amount memory currently used by ring_buffer
- Inside parent node are <event> nodes
- Contain information returned by events defined in event session.
- event_file
- file system storage
- proprietary binary format
- Supports max size and rollover.
- Same XML format as ring_buffer
- options
- filename
- specifies location and file name of log file and is the only required option
- filename is appended with _0_ and then date in milliseconds
- max_file_size
- default 1GB
- max_rollover_files
- Configures max number of files to retain during rollover
- increment
- Configures size in MB to grow log file each time it runs out of space
- Default value is twice the size of memory buffers for the session
- metadatafile
- location of metadata file that corresponds to the log file for the session
- Not used 2012+
- Used in 2008/2008R2
- filename
- sys.fn_xe_file_target_read_file
- table-valued function used to read event_file data.
- parameters
- path – path of files to read. Can contain wildcards.
- mdpath – path to metadata file. Not used in 2012
- initial_file_name – first file to read from path. null – all files found in path are read.
- initial_offset – offset in teh first file where reading begins. null – the entire fill will be read
- initial_file_name and initial_offset are paired. specifying one, requires the other.
- ring_buffer
- Isolation levels
- READ UNCOMMITTED
- Do not issue shared locks, therefor doesn’t prevent other transactions from modifying data read by the current transaction.
- Transactions are not blocked by exclusive locks at the time of data modification.
- READ COMMITTED
- Default
- Issues exclusive locks during data modification, not allowing other transactions to read the modified data not yet committed.
- Prevents Dirty Read.
- Other transactions can change data between individual statements within the transaction, resulting in non-repeatable read and phantom rows.
- READ_COMMITTED_SNAPSHOT
- Off (default)
- Shared locks prevent other transactions from modifying rows while current transaction is reading.
- Shared locks also block the statement from reading rows modified by other transactions until the other transaction is completed.
- On (Default in SQL Azure)
- Row versioning is used to provide consistency. No locks are issued.
- Off (default)
- REPEATABLE READ
- Statements cannot read data that has been modified but not committed by other transactions.
- No other transaction can modify data that has been read by the current transaction until the current transaction completes.
- Shared locks are placed on all data read by each statement in the transaction and are held until the transaction completes.
- Other transactions can’t modify rows that have been read by the current transaction.
- Prevents non-repeatable read problem
- Other transactions can insert rows that match the search conditions of the statements issued by the current transaction, resulting in phantom reads.
- Prevents lost updates.
- Key range locks are not taken.
- SERIALIZABLE
- Statements cannot read data that has been modified but not yet committed by other transactions.
- No other transaction can modify data that has been read by the current transaction until the transaction completes.
- Other transactions cannot insert new rows with key values that would fall in teh range of keys read by any statements in the current transaction until transaction completes, preventing phantom reads.
- SNAPSHOT
- Data read in any statement in transaction will be the transcriptional consistent version of the data that existing at the start of the transaction.
- Data modifications made by other transactions after the start of the current transaction are not visible to statements in the current transaction.
- Snapshot transactions do not request locks when reading.
- Reading data does not block other transactions writing data.
- Writing data do not block snapshot transactions from reading data.
- READ UNCOMMITTED
- Consistency issues
- Dirty reads
- (Uncommitted dependency)
- When you read data from other transactions that could be rolled-back.
- Non-repeatable reads
- (Inconsistent analysis)
- You read data but you read it again and it’s different.
- Phantom reads
- When rows are inserted when you read a range of rows twice.
- Lost updates
- https://docs.microsoft.com/en-us/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide?view=sql-server-ver15
- Occurs when two or more transactions select the same row and then update the row based on the value originally selected.
- Each transaction is unaware of the other transactions.
- The last update overwrites updates made by the other transactions, which results in lost data.
- Missing and double reads caused by row updates
- Missing a updated row or seeing an updated row multiple times.
- Transactions running in READ UNCOMMITTED do not issue shared locks to prevent other transactions from modifying data read by the current transaction.
- READ COMMITTED does issue shared locks, but row or page locks are released after row is read.
- Row is added during a scan is one example.
- To avoid, use serializable or HOLDLOCK hint, or row versioning (snapshot)
- Missing one or more rows that were not the target of an update
- When using READ UNCOMMITTED, if query reads rows using allocation order scan (using IAM pages), you could miss rows if another transaction is casing a page split.
- This cannot occur if you are using READ COMMITTED because a table lock is held during a page split and does not happen if the table does not have a clustered index, because updates do not cause page splits.
- When using READ UNCOMMITTED, if query reads rows using allocation order scan (using IAM pages), you could miss rows if another transaction is casing a page split.
- Missing a updated row or seeing an updated row multiple times.
- Dirty reads
- SQL Server Resource Governor
- Resource pools are separated into two parts.
- Minimum resource reservations allow for the isolation of resources from other workloads.
- Maximum resource reservations will allow for shared resources across workloads.
- Resource pools are separated into two parts.
- Cardinality estimator
- Will use EQ_ROWS if the value exists in the RANGE_HI_KEY column.
- Will use AVG_RANGE_ROWS when a value does not exist in the RANGE_HI_KEY column, but falls with the range of a given row and the previous row.
- Locks
- ACID Properties
- Atomicity
- Transaction must be an atomic unit of work. All modifications are performed, or none.
- Consistency
- When completed, all data must be in a consistent state.
- Isolation
- Concurrent transactions must be isolated from modifications made by any other concurrent transactions.
- Referred to as serializbility because it results in the ability to reload the starting data and replay a series of transactions to end up with the data in the same state it was in after the original transactions were performed.
- Durability
- After completion, effects are permanently in place in the system.
- Modifications persist even in the event of a system failure.
- 2014+ enabled delayed durable transactions.
- Transactions commit before the transaction log record is persisted to disk.
- Atomicity
- Batch-scoped transactions
- Applicable only to MARS (multiple active result sets)
- A explicit or implicit transaction that starts under a MARS session becomes a batch-scoped transaction.
- A batch-scoped transaction that is not committed or rolled back when a batch completes is automatically rolled back by SQL Server.
- Distributed Transactions
- Span two or more servers known as resource managers.
- Management of the transaction must be coordinated between the resource managers by a server component called a transaction manager.
- Each instance of SQL Server Database Engine can operate as a resource manager in distributed transactions coordinated by transaction managers, such as MS DTC (Microsoft Distributed Transaction Coordinator), or other transaction managers that support the Open Group XA specification for distributed transaction processing.
- A transaction in a single instance of SQL Server, that spans two or more databases is a distributed transaction.
- The instance manages the distributed transaction internally; to the user it operates as a local transaction.
- A distributed commit must be managed differently by the transaction manager to minimize the risk that a network failure may result in some resource managers successfully committing while others roll back the transaction. This is achieved by managing the commit process in two phases: the prepare phase and the commit phase, known as a two-phase commit.
- Prepare phase
- When transaction manager receives a commit request, sends a prepare command to all other resource managers involved.
- Each resource manager then does everything required to make the transaction durable, and all buffers holding log images for the transaction are flushed to disk.
- As each resource manager completes the prepare phase, returns success or failure of the prepare to the transaction manager.
- Commit phase
- If transaction manager receives successful prepares from all of the resource managers, sends commit commands to each resource manager.
- Resource managers can then complete the commit.
- If all resource managers report a successful commit, transaction manager then sends a success notification to the application. If any manger reported a failure to prepare, the transaction manager sends a rollback command to each resource manager and indicates the failure of the commit to the application.
- Prepare phase
- Every database connection holds a shared database lock.
- Intent shared locks are held until a transaction is committed or rolled-back and indicate that other locks are held at lower levels.
- May only be true for REPEATABLE READ? When selecting.
- Intent Shared (IS) lock is compatible with Intent Exclusive (IX).
- Intent Exclusive is a superset of Intent Shared. IS is the only lock compatible with IX.
- There can only be one Shared Intent Exclusive (SIX) lock on a resource. This lock prevents updates by other transactions.
- Only one transaction can obtain an update lock on a resource at a time.
- Lock Granularity
- RID
- Row identifier, used to lock a single row in a heap.
- KEY
- Row lock within an index used to protect key ranges in serializable transactions.
- PAGE
- 8KB page in a database, such as data or index pages.
- Can’t tell if they actually mean KiB
- 8KB page in a database, such as data or index pages.
- EXTEND
- Contigious group of eight pages, such as data or index pages.
- HoBT
- Heap or B tree
- Lock protecting B tree index, or heap data pages in a table that does not have a clustered index (is not a heap)
- Can be affected by LOCK_ESCALATION option of ALTER TABLE.
- TABLE
- Entire table, including data and indexes.
- Can be affected by LOCK_ESCALATION option of ALTER TABLE.
- FILE
- Database file.
- APPLICATION
- Application-specified resource.
- METADATA
- Metadata lock.
- ALLOCATION_UNIT
- DATABASE
- RID
- Lock Modes
- S
- Shared
- read operations that do not change data
- e.g. SELECT
- Allow concurrent transactions to read under pessimistic concurrency control.
- No other transactions can modify data while shared lock exists on resource.
- Released as soon as read operation completes, unless isolation level is REPEATABLE READ or higher, or locking hint is used to retain shared locks for the duration of the transaction.
- U
- Update
- Resources that can be updated.
- Prevents common deadlock that occurs when multiple sessions are reading, locking, potentially updating resources later.
- Used to prevent the following scenario:
- X
- Exclusive
- Data modification operations.
- Ensures multiple updates cannot be made to same resource at same time.
- e.g. INSERT, UPDATE, DELETE
- I
- Intent
- Used to establish lock hierarchy.
- Indicates other locks are held at lower levels.
- IS
- Intent Shared
- IX
- Intent Exclusive
- SIX
- Shared Intent Exclusive
- Sch
- Schema
- Operation dependent on schema of table is executing.
- Sch-M
- Schema modification
- Sch-S
- Schema stability
- BU
- Bulk Update
- Bulk copying data into a table and TABLOCK hint is specified.
- Key range
- Protects range of rows read by a query when using serializable transaction isolation level.
- Ensures other transactions cannot insert that would quality for the queries of the serializable transaction if the queries were run again.
- S
- ACID Properties
- DMVs
- sys.dm_exec_query_stats
- Will evaluate the performance of individual statements within natively compiled stored procedures. One row per query statement within the cached plan.
- sys.dm_exec_procedure_Stats
- One row per natively compiled stored procedure.
- sys.pdw_nodes_exec_query_Stats.
- Used for Azure SQL Data Warehouse or Parallel Data Warehouse. Not used in Enterprise Edition.
- sys.pdw_nodes_exec_procedure_stats.
- Same as above.
- sys.dm_exec_session_wait_stats
- Displays information about the actual wait statistics in the connection to a particular session.
- sys.dm_exec_query_stats
- Will show stats for cached query plans
- sys.dm_db_resource_Stats
- Is used to see resource consumption of cpu/data io/memory
- sys.dm_operation_status
- Is used to find information about operations that have been performed on an azure sql database.
- sys.dm_db_log_stats
- DMV is used to find information on transaction og files of a database. Used for monitoring transaction log health.
- sys.dm_db_missing_index_group_stats
- DMV to determine the impact of an index group would have if it was created. Returns statistics such as avg_system_impact and avg_total_system_cost which shows the amount of impact an index would have.
- sys.dm_db_missing_index_columns
- Returns column information about hte missing indexes and dose not return statistics.
- sys.dm_db_missing_index_details
- Returns information about missing index such as column informatino and statement used to create the missing index.
- sys.dm_db_missing_index_groups
- Returns information that relates an index group to an index.
- sys.dm_db_index_usage_Stats
- Contains statistics for indexes built on disk-based tables. Not used for memory-optimized.
- exec sp_query_store_force_plan [query id] [plan id]
- This forces the given query plan to be used.
- sys.dm_exec_cached_plans
- Used to find the reuse count of each cached query plan in the procedure cache.
- Can be used to see cached query plans, cached query text, and memory used by cached plans.
- sys.dm_db_query_stats
- Used to find aggregated performance statistics for cached query plans.
- sys.dm_Exec_requests
- Used to find information about each execution request that is currently executing in SQL Server.
- sys.dm_db_xtp_index_stats
- This view contains the statistics for indexes that are built on memory-optimized tables since the last database restart.
- There’s no DMVs that will show DTU consumption.
- sys.dm_exec_query_stats
- SET IMPLICIT_TRANSACTIONS ON
- BEGIN TRANSACTION is optional
- Explicit transactions require the BEGIN TRANSACTION statement.
- COMMIT, ROLLBACK, SAVE statements would be required in both implicit and explicit.
- you cannot handle or throw exceptions in a function. Stored procedures can.
- Resource governing: MAX_CPU_PERCENT doesn’t enforce a max, it enforces a max average. So, you could actually go over the max as long as it’s less than the average. CAP_CPU_PERCENT places a hard cap.
- SQL Profiler Trace can capture deadlocks in XML format. Trace flag 1222 automatically records all deadlocks in XML format in SQL Server Error Log Trace flag 1224 disables lock escalation based on the number of locks.
- If you have a View with a where clause and want the view to continue to return the updated record in the result set, specify WITH CHECK OPTION in the WHERE clause. This checks that teh result of INSERT/UPDATE/DELETE are still visible to the user of the view.
- “Forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.”
- Don’t use Performance Recommendation in Azure portal for individual queries. It shows recommendations like building indexes, but not resource consumption for individual queries.
- Query Performance Insite in Azure portal is used for individual queries running in Azure SQL database.
- ALTER INDEX indexname ON tableName REOGANIZE
- defragments index and keeps it online to minimize impact on query perf
- REBUILD drops and recreates the index, which negatively affects query performance until index is rebuilt.
- Use an Action object to add the session ID to an extended event.
- Granting SHOWPAN is only applicable to users authenticated by SQL Server.
- Granting role-based access control of Reader doesn’t give the user the ability to view the query text used to execute the query.
- Use SQL Server Profiler to capture deadlocks.
- Columnstore Indexes
- The standard for storing and querying large data warehousing “fact tables”
- Index uses column-based data store and querying processing to achieve query performance and data compression over traditional storage.
- A technology for storing, retrieving, and managing data by using a columnar data format, called a columnstore.
- Terms
- Columnstore data is logically organized as a table with rows and columns, and physically stored in a column-wise format.
- Rowstore is logically organiazed as a table with rows and columns, and physically stored in a row-wise data format. This is the traditional way.
- Rowgroup is a group of rows that are compressed into a columnstore format at the same time. Usually contains the max number of rows per rowgroup, which is 1048576.
- For high performance and high compression rates, columnstore nidex slices the table into rowgroups, then compresses each rowgroup in a column-wise manner. The number of rows in the rowgroup must be large enough to improve the compression rate, and small enough to benefit from in-memory operations.
- Column segment is a column of data from within the rowgroup.
- Each rowgroup contains one column segment for every column in the table.
- Each column segment is compressed together and stored on physical media.
- Clustered columnstore index is the physical storage for the entire table.
- To reduce fragmentation of the column segments and improve performance, the columnstore index might store some data temporarily into a clustered index called a delstastore and a btree list of IDs for deleted rows.
- Deltastore operations are handled behind the scenes. To return the correct query results, the clustered columnstore index combines query results from both the columnstore and the deltastore.
- Delta rowgroup is a clustered index that’s used only with columnstore indexes. Improves columnstore compression and performance by storing rows until the number of rows reaches a threshold and are then moved into the columnstore.
- When a delta rowgroup reaches the maximum number of rows, it becomes closed. A tuple-mover process checks for closed row groups. If the process finds a closed rowgroup, it compresses the rowgroup and stores it into the columnstore.
- Deltastore
- A columnstore index can have more than one delta rowgroup. All of the delta rowgroups are called a deltastore.
- During a large bulk load, most rows go directly to the columnstore without passing through the deltastore. Some rows at teh end of the bulk load might be too few in number to meet the min size of the rowgroup, which is 102,400 rows. As a result, the final rows go to the deltastore instead of the columnstore. For small bulk loads with less than 102,400 rows, all of the rows go directly to the deltastore.
- Nonclustered columnstore index
- Function the same as a clustered columnstore index.
- Difference is that a nonclustered index is a secondary index that’s created on a rowstore table, but a clustered columnstore index is the primary storage for the entire table.
- The nonclustered index contains a copy of part of all of the rows and coumns in the underlying table. The index is defined as one or more columns of the table and has an optional condition that filters the rows.
- A nonclustered columnstore index enables real-time operational analytics where the OLTP workload uses teh underlying clustered index while analytics runs concurrently on the columnstore index.
- Batch mode execution
- A query processing method that’s used to process multiple rows together. Batch mode execution is closed integrated with and optimized around the columnstore storage format.
- Batch mode execution is sometimes known as vector-based or vectorized execution.
- Queries on columnstore indexes use batch mode execution, which improves query performance typically by two or four times.
- Why use a columnstore index?
- Can provide high data compression (typically 10x). Significantly reduces data warehouse storage cost.
- Order of magnitude better performance than btree index.
- Stores values from the same domain and commonly have similar values, resulting in high compression rates. Nearly eliminates IO bottlenecks.
- High compression rates improve query perf by using smaller memory footprint.
- Batch execution improves query perf, typically 2x – 4x, by processing multiple rows together.
- Queries often select only a few columns from a table, reducing total IO from storage.
- Preferred storage format for data warehousing & analytics workloads.
- When should they be used?
- Use clustered columnstore index to store fact tables and large dimension tables for data warehousing workloads.
- A “fact table” is a central table in a star schema of a data warehouse. Store quantiative information for analysis and is often denormalized.
- Fact tables work with dimension tables.
- A “star schema” is the simplest form of a dimensional model, in which data is organized in facts and dimensions.
- A fact is an event that is counted or measured, such as sale or login.
- A dimension contains reference information about the fact, such as date, product, or customer.
- A star schema is diagramed by surrounding each fact with its associated dimensions.
- A “fact table” is a central table in a star schema of a data warehouse. Store quantiative information for analysis and is often denormalized.
- Use nonclustered columnstore index to perform analysis in real time on OLTP workloads.
- Use clustered columnstore index to store fact tables and large dimension tables for data warehousing workloads.
- Using partition switching requires column store index to be partition-aligned.
- Batch execution mode allows query execution operators to call a function that returns several rows at a time instead of a single row at a time.
- Adding a nonclustered column store index (as of 2012) locks down some data modification capabilities. You cannot perform:
- Insert, update delete, merge bcp/bulk insert.
- Save points
- SAVE { TRAN | TRANSACTION } { savepoint_name | @savepoint_variable }
- savepoint_name are limited to 32 characters. case sensitive always.
- Defines a location to which a transaction can return if part of the transaction is conditionally canceled.
- If a transaction is rolled back to a savepoint, it must proceed to completion with more tsql statements if needed and a COMMIT TRANSACTION, or must be canceled altogether by rolling the transaction back to its beginning.
- Cancel the entire transaction with ROLLBACK TRANSACTION transaction_name
- Duplicate savepoint names are allowed in a transaction.
- But a ROLLBACK TRANSACTION statement that specifies the savepoint name will only roll back to the most-recent SAVE TRANSACTION using that name.
- Not supported in distributed transactions started explicitly or escalated from a local transaction.
- A ROLLBACK TRANSACTION statement specify a savepoint name releases any locks acquired beyond the savepoint, except escalations and conversions. These locks are not released, but converted back to their previous lock mode.
- SAVE { TRAN | TRANSACTION } { savepoint_name | @savepoint_variable }
- User-defined functions
- https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sql-server-2017
- Scalar
- — Transact-SQL Scalar Function Syntax CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name ( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type [ = default ] [ READONLY ] } [ ,…n ] ] ) RETURNS return_data_type [ WITH <function_option> [ ,…n ] ] [ AS ] BEGIN function_body RETURN scalar_expression END
- Table-Valued
- — Transact-SQL Inline Table-Valued Function Syntax
- CREATE [ OR ALTER ] FUNCTION [ schema_name. ] function_name ( [ { @parameter_name [ AS ] [ type_schema_name. ] parameter_data_type [ = default ] [ READONLY ] } [ ,…n ] ] ) RETURNS TABLE [ WITH <function_option> [ ,…n ] ] [ AS ] RETURN [ ( ] select_stmt [ ) ]
- There’s also multi-statement table-valued functions
- Elastic Scale Azure SQL Database
- Implement shard map management when implementing elastic scale on an azure sql database.
- Allows you to register each database as a shard. A shard map manager will be defined that directs connection requests to the correct shard.
- data-dependent routing allows you to define and assign a connection to the correct shared.
- multi-shard querying is used by the database engine to process queries in parallel across shards.
- Shard elasticity is a feature used to monitor resource consumption and will dynamically assign more resources or deallocate resources.
- SQL Database elastic pools are a cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands.
- Databases in an elastic pool are on a single azure sql database server.
- Common application pattern is one database per customer
- Different customer have varying usage patterns – makes it difficult to predict resource requirements.
- Elastic pools solves this problem by ensuring each database get the performance resources that they need.
- Implement shard map management when implementing elastic scale on an azure sql database.
- Assign the value of a stored procedure to a variable
- EXEC @ReturnValue = Website.ListOverdueOrders;
- When you change an index’s options, you must rebuild.
- When you want a stored procedure to be permitted to access the required tables and the owner of the stored procedure has permissions, include the WITH EXECUTE AS OWNER clause.
- Change the locking strategy to escalate to the partition level instead of the table level
- ALTER TABLE [table] SET (LOCK_ESCALATION=AUTO)
- This will cause locks to be escalated to the partition level. There’s no other explanation.
- xact_abort off
- When off, errors in a transaction will be statement terminating.
- When on, errors in a transaction will be batch terminating.
- SQL Audit is implemented as a secure Extended Events package. You cannot modify the SQL Audit actions but you can implement the same options by using Extended Events.
- In READ UNCOMMITTED, no locks are taken on select statements. There would just be a shared lock on the database.
- Stored procedures
- Design stored procedure components and structure
- Implement input and output parameters
- Implement table-valued parameters
- Implement return codes
- Streamline existing stored procedure logic
- Implement error handling and transaction control logic within stored procedures
- A group of one or more sql statements or a reference to a CLR method.
- Can accept input parameters and return multiple values (using output parameters)
- Can call other procedures
- Can return a status value to indicate success or failure.
- Benefits
- Reduce server/client network traffic
- Otherwise the app would have to implement the logic, resulting in more back-and-forht
- Stronger security
- Multiple users/programs can perform operations on underlying database objects even if users don’t have direct access to the underlying objects.
- EXECUTE AS enables impersonating another user
- Some actions like TRUNATE TABLe don’t have grantable permissions. Instead you could implement a store procedure and give the user access to that.
- When calling over the network, only the call to execute procedure is visible. If malicious users are able to sniff traffic, they won’t be able to see database object names/data.
- Helps guard against SQL injection.
- Parameter input is treated as a literal value and not as executable code, making it more difficult to insert a command and compromise security.
- Procedures can be encrypted, obfuscating the source code.
- Code reuse
- Contain repetitious database operations.
- Easier Maintenance
- Client apps who call procedures, keeps database operations in the data tier. Only the procedures would need to be updated and application code wouldn’t need to change.
- Improved performance
- Procedure compiles the first time it is executed and creates an execution plan that is reused.
- Because the query processor doesn’t have to create a new plan, it takes less time to process the procedure.
- Reduce server/client network traffic
- Types
- User-defined
- Can be defined in a user-defined database or in all system databases except the resource database.
- Can be either TSQL or SQL CLR
- Temporary
- A form of user-defined procedure
- Act like permanent, except these are stored in tempeh.
- Two types
- local
- have a single number sign (#) as the first character of their names. Only visible to the current user connection.
- Deleted when connection is closed.
- global
- Have two number signs (##) as the first two characters of their names.
- Visible to any user after they are created.
- Deleted at the end of the last session using the procedure.
- local
- System
- Included with SQL Server
- Stored in the internal, hidden Resource database and logically appear in sys schema of every system and user-defined database.
- msdb database also contains system procedures in the duo schema and are used for scheduling alerts and jobs.
- Because system procedures start with the prefix sp_, it’s recommended that you do not use this prefix when naming user-defined procedures.
- Extended user-defined
- Enables creating routines in other programming languages, like C.
- These are DLLs that SQL Server dynamically loads and runs.
- These are deprecated and will be removed in a future release. Use SQL CLR.
- User-defined
- Procedure can have max of 2100 parameters,
- Parameter values supplied to a procedure call must be constants or a variable. Function names cannot be used as a value.
- EXEC dbo.uspGetWhereUsedProductID 819, ‘20050225’;
- Passing values as variables.
- DECLARE @ProductID int, @CheckDate datetime; SET @ProductID = 819; SET @CheckDate = ‘20050225’; EXEC dbo.uspGetWhereUsedProductID @ProductID, @CheckDate;
- CREATE PROCEDURE Production.uspGetList @Product varchar(40) , @MaxPrice money , @ComparePrice money OUTPUT , @ListPrice money OUT AS …
Requirements
- Design tables and schemas
- Use normalization
- Determine the most efficient data types to use
- Indexes
- Design new indexes based on provided tables, queries, or plans
- Distinguish between indexed columns and included columns
- Implement clustered index columns by using best practices; recommend new indexes based on query plans
- Views
- Design a view structure to select data based on requirements
- identify the steps necessary to design an updateable view
- implement partitioned views
- implement indexed views
- Columnstore indexes
- Determine use cases that support the use of columnstore indexes
- Identify proper usage of clustered and non-clustered columnstore indexes
- Design standard non-clustered indexes in conjunction with clustered columnstore indexes
- Implement columnstore index maintenance
- Constraints
- Define table and foreign key constraints
- Add constraints to tables
- Identify results of Data Manipulation Language (DML) statements given existing tables and constraints,
- Identify proper usage of PRIMARY KEY constraints
- Stored procedures
- Design stored procedure components and structure
- Implement input and output parameters
- Implement table-valued parameters
- Implement return codes
- Streamline existing stored procedure logic
- Implement error handling and transaction control logic within stored procedures
- Triggers and user-defined functions
- Design trigger logic
- Determine when to use Data Manipulation Language (DML) triggers
- Data Definition Language (DDL) triggers
- Logon triggers
- Recognize results based on execution of AFTER or INSTEAD OF triggers
- Design scalar-valued and table-valued user-defined functions
- Identify differences between deterministic and non-deterministic functions
- Transactions
- Identify DML statement results based on transaction behavior
- Recognize differences between and identify usage of explicit and implicit transactions
- Implement savepoints within transactions
- Determine the role of transactions in high-concurrency databases
- Manage isolation levels
- Identify differences between Read Uncommitted, Read Committed, Repeatable Read, Serializable, and Snapshot isolation levels; define results of concurrent queries based on isolation level; identify the resource and performance impact of given isolation levels
- Optimize concurrency and locking behavior
- Troubleshoot locking issues, identify lock escalation behaviors, capture and analyze deadlock graphs, identify ways to remediate deadlocks
- Implement memory-optimized tables and native stored procedures
- Define use cases for memory-optimized tables versus traditional disk-based tables, optimize performance of in-memory tables by changing durability settings, determine best case usage scenarios for natively compiled stored procedures, enable collection of execution statistics for natively compiled stored procedures
- Optimize statistics and indexes
- Determine the accuracy of statistics and the associated impact to query plans and performance, design statistics maintenance tasks, use dynamic management objects to review current index usage and identify missing indexes, consolidate overlapping indexes
- Analyze and troubleshoot query plans
- Capture query plans using extended events and traces, identify poorly performing query plan operators, create efficient query plans using Query Store, compare estimated and actual query plans and related metadata,
- Configure Azure SQL Database Performance Insight
- Manage performance for database instances
- Manage database workload in SQL Server
- Design and implement Elastic Scale for Azure SQL Database
- select an appropriate service tier or edition
- optimize database file and tempdb configuration;
- optimize memory configuration
- monitor and diagnose scheduling and wait statistics using dynamic management objects
- troubleshoot and analyze storage, IO, and cache issues
- monitor Azure SQL Database query plans
- Monitor and trace SQL Server baseline performance metrics
- Monitor operating system and SQL Server performance metrics
- Compare baseline metrics to observed metrics while troubleshooting performance issues
- Identify differences between performance monitoring and logging tools, such as perfmon and dynamic management objects
- Monitor Azure SQL Database performance
- Determine best practice use cases for extended events
- Distinguish between Extended Events targets
- Compare the impact of Extended Events and SQL Trace
- Define differences between Extended Events Packages, Targets, Actions, and Sessions
INSTEAD OF trigger Query Performance Insight Normal forms
Table partitions sys.stats sp_autostats sys.stats_columns DML trigger Trace flag 1222 Online rebuilding of index is not supported in 2016 Standard. Online rebuilding of non clustered columnstore indexes is only in SQL 2016 Enterprise SP1 or higher. Disabling clustered columnstore indexes disables access to the table. Executing sp_autostats will show when stats were last updated. Another option is executing stats_date function with table’s obect_id and stats_id for each statistic on the table.
ddl trigger => creating a table
- create
- alter
- drop
dml trigger => modifying a table.
- insert
- update
- delete
When alerts fire, they’re sent to Operators. 0 is low process priority, 5 is high.
reorganize indexes?
- Use multi-shared querying when you want to ensure the database engine will process queries in parallel across shards using elastic scale.
- Shard elasticity is used to monitor resource consumption and dynamically assign more resources or deallocate resources
- Shard map management allows you to register each database as a shard. It then defines a shard map manager that directs connection requests to the correct shard.
- Data-dependent routing allows you to automatically define and assign a connection to the correct shard.
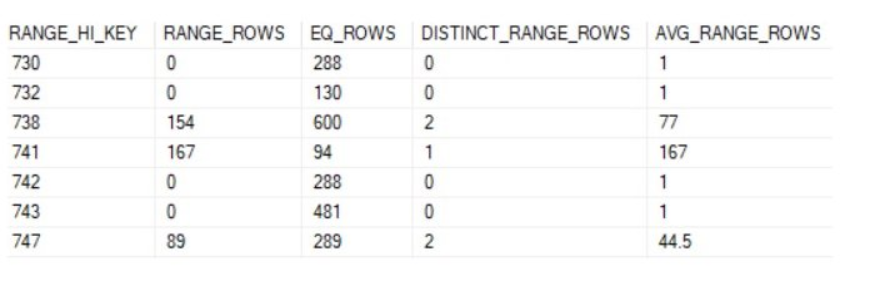
- RANGE_ROWS
- Used to specify how many records exist between the value listed in RANGE_HI_KEY of a given row and the previous row.
- In the above, there’s 154 rows between 732 and 738
- Used to specify how many records exist between the value listed in RANGE_HI_KEY of a given row and the previous row.
- AVG_RANGE_ROWS
- Used by the cardinality estimator when a value does not exist in RANGE_HI_KEY, but falls within the range of a given row and the previous row.
- This value is calculated by dividing RANGE_ROWS by the DISTINCT_RANGE_ROWS.
- RANGE_ROWS/DISTINCT_RANGE_ROWS=AVG_RANGE_ROWS
- By default, statistics are created for indexes that are created on a table.
- RANGE_HI_KEY column in the stats matches the key field from the index. If a value exists in RANGE_HI_KEY, the cardinality estimator will return the value in EQ_ROWS
- DISTINCT_RANGE_ROWS
- Used to specify how many unique values exist between the value listed in the RANGE_HI_KEY field of a row and the previous row.
- In the above, there are 2 unique values between 732 and 738.
Configure SQL Server to notify you when alerts occur
- Configure an Operator.
- When alerts fire, notifications can be sent to operators.
- Notifications can be associated with email addresses.
- TABLOCKX hint
- Sets an exclusive lock on teh table.
- HOLDLOCK hint
- Equivalent to the serializable transaction isolation level.
hash indexes are optimized for equality seeks. They might only apply to memory optimized tables.
free practical lab demo
with view_metadata? with check option? sql server resource governor sp_autostats what does “federate” mean benefits of hash index because only being in memory optimized? stored prcoedure vs table valued function What is System Monitor?
online rebuilding of columnstore index is not supported in sql server standard configuring alerts raised by sql server: errors 823, 824, 829 are for IO subsystem. error severity 17 or higher are system errors. (10 or lower are information), (11-16 are client errors (e.g. syntax))
cross-database integrity between different keys in two database servers: don’t use foreign keys. Use triggers. foreign keys can only be used on the same server. Trigger is the only way to accomplish this.
WITH CHECK OPTION: checks that the result of an insert/update/delete statement are still visible to the user of the view.
sp_autostats – can display or change the automatic statistics update options. When executed with just table name, returns last time each stat built on the table was calculated.
sys.stats returns informatino about statistics, but not the last time a stat was calculated. sys.stats_columns returns information about columns that are included in stats, but not the last time stats were calculated for a table.
hash indexes are optimized for equality seeks.
table-valued procedure prameters must all be declared readonly